一、数据库环境搭建
首先你需要有一个MySQL数据库,无论是本地的还是远程的都可以,其次我们需要在虚拟环境中安装SQLAlchemy,这是用来创建数据表模型的,具体安装:
pip install sqlalchemy==1.4.18
接着还需要安装pymsql工具,它是用来连接数据库的:
pip install pymysql==1.0.2
这样数据库相关的包已经准备完毕了。
二、数据库模型设计
我们需要使用SQLAlchemy来创建模型表,所以需要依赖于它基本的模型类。
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
在models.py文件:
from database import Base from sqlalchemy import Column, String, Integer, Float, DateTime, ForeignKey from sqlalchemy.orm import relationship import datetime """ 创建四个模型表: 1、书籍模型表 2、出版社模型表 3、作者模型表 4、出版社于书籍多对多关系模型表 """ class Book(Base): __tablename__ = "book" id = Column(Integer, primary_key=True, index=True) title = Column(String(32)) price = Column(Float) publish_date = Column(DateTime, default=datetime.datetime.now) author_id = Column(Integer, ForeignKey("author.id")) class Author(Base): __tablename__ = "author" id = Column(Integer, primary_key=True, index=True) username = Column(String(32), index=True) email = Column(String(32)) author_to_book = relationship("Book", backref="book_to_author") class Publish(Base): __tablename__ = "publish" id = Column(Integer, primary_key=True, index=True) name = Column(String(32)) publish_to_book = relationship("Book", backref="book_to_publish", secondary="match") class Match(Base): __tablename__ = "match" id = Column(Integer, primary_key=True, index=True) publish_id = Column(Integer, ForeignKey("publish.id")) book_id = Column(Integer, ForeignKey("book.id"))
在database.py文件中创建数据库引擎,连接到数据库(需要先创建好数据库):
from sqlalchemy.engine import create_engine DATABASE_URL = "mysql+pymysql://root:[email protected]:3306/test" engine = create_engine(DATABASE_URL, encoding="utf8", echo=True)
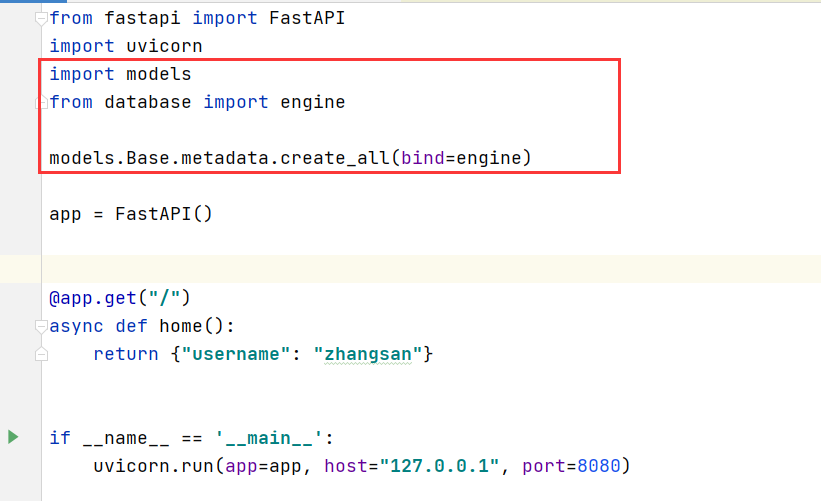
在main.py文件中继续添加如下代码:
from database import engine models.Base.metadata.create_all(bind=engine)
注意这里一定要使用models中的Base基类,因为它已经有你注册的模型表的元数据。
执行main.py文件,此时生成数据表。
三、数据库模型表迁移
(一)Alembic初始化
虽然上面的可以生成数据库表了,但是后期根据需求还是会随时增加或者减少字段这类的变动,所以需要一个工具来进行迁移文件的管理以及生成对应的数据库模型表,Alembic可以很好的解决这个问题。
pip install alembic==1.6.5
在项目的根目录下执行下面的命令进行初始化:
alembic init alembic
此时在项目的根目录下生成alembic文件夹以及alembic.ini配置文件:
在alembic.ini修改数据库的连接配置:
sqlalchemy.url = mysql+pymysql://root:[email protected]:3306/test
- 在alembic文件夹中的env.py文件中修改target_metadata
import models ... target_metadata = models.Base.metadata ...
(二)使用Alembic
将当前数据库的状态生成迁移文件:
alembic revision --autogenerate -m "generate tables"
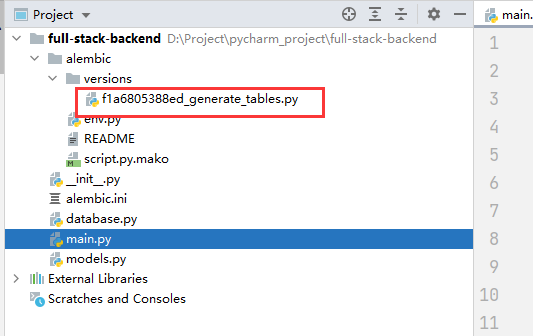
此时会在alembic目录下的version目录下生成一个新的迁移文件:
这一步是将迁移文件中的动作在数据据中执行,生成对应的表之类的操作:
alembic upgrade head
此时数据表已经成功生成了。